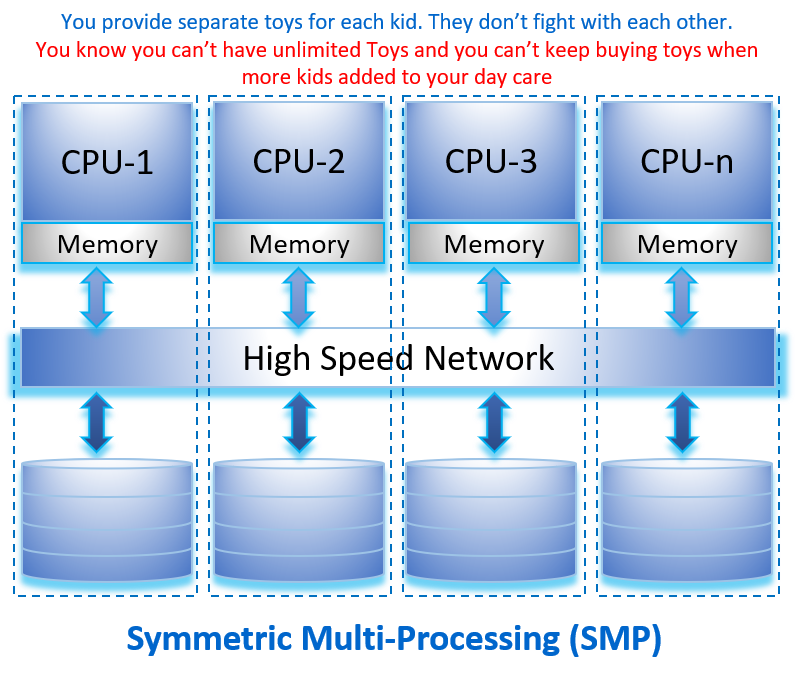
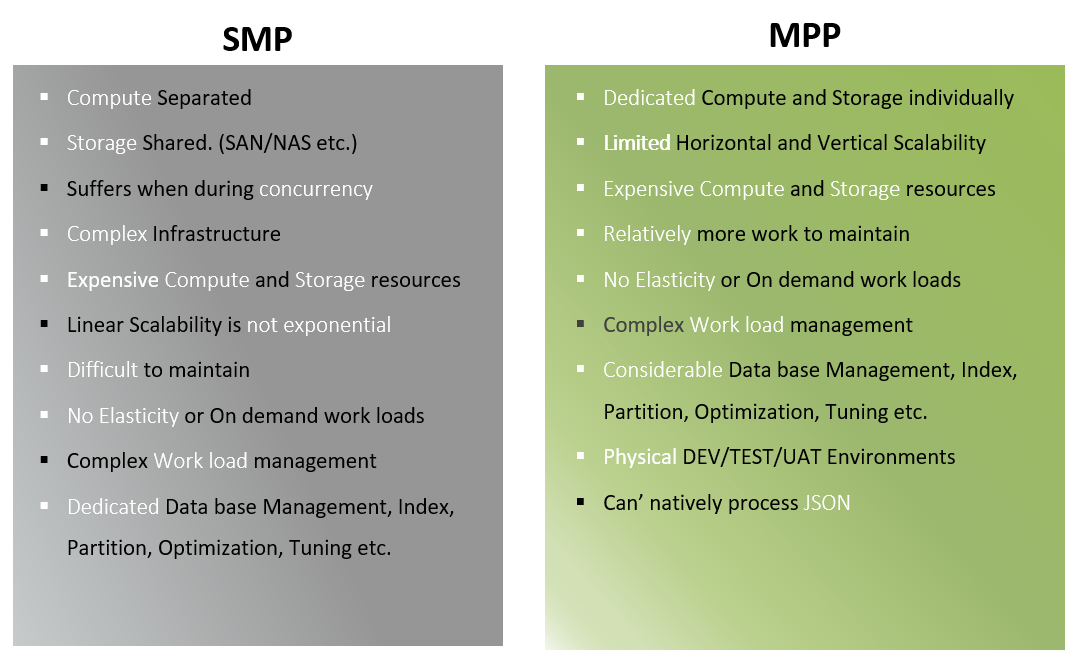
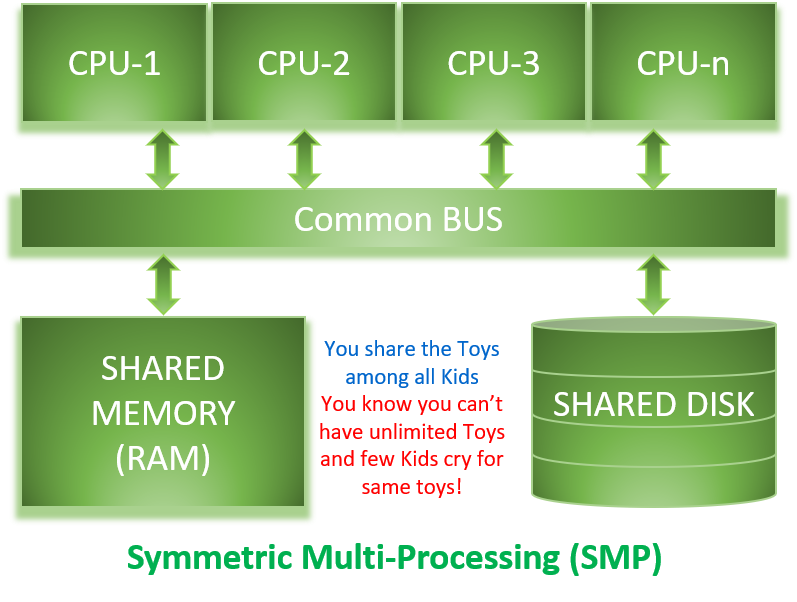
Databricks Autoloader
Dear readers, I will slow down on Databricks blog after this one since I strongly believe in Technology DEI (Diversity, Equity, and Inclusion) is very important for all of us.
I also had a LinkedIn poll to get your thoughts on the kinds of blogs you all would like to see..
- Tech, Uses Cases & Humor (94% Votes) – This blog is tailored for you
- Tech & Uses Cases (3% Votes) – Ignore “Real life examples” sections
- Tech only (3% Votes) – Ignore Use Cases and “Real life example”. Check databricks.com for deep dives
Thanks for responding to the poll. Let us keep having some fun in sharing our thoughts.
Thank you very much Asjad Husain for your great editing job on this blog.
Why did I choose Databricks’ Autoloader as next topic for our discussion? After reading the Delta Li(o)ve tables blog, some of you have asked me about;
- How is the data received by the Delta Live Tables (DLT)?
- What do I mean by Autoloader?
- Why can’t we build the Autoloader using Hyperscalers (AWS, Azure, GCP etc.) provided technologies (Do It Yourself – DIY)?
Before you start reading this blog, a disclaimer;
- This is not a comparison of Databricks Autoloader with other technologies like Snowflake Snowpipe, GCP Big Query streaming inserts, AWS Kinesis set of tools, Azure Event Hub / Event Grid with Azure Stream Analytics, Confluent Kafka Streaming with KSQL, Apache Flink, Apache Storm, or any other competing technology available on the cloud including the hyperscalers.
- I practice and advise our clients on the above-mentioned technologies and many others based on their enterprise strategy without taking a bias on one technology over another.
- Every vendor brings new capabilities. I admire, appreciate, and challenge them to make the world better with their innovative creations.
- I generally write blogs for my friends, who are non-technologists, but are very interested in learning and talking about new technologies.
- If you are looking for hands-on or looking for sample codes, my recommendation is to use google to find so many great ready-to-run examples. I highly recommend checking databricks.com.
- Pardon me for the longer blog. The goal was to keep the thought process alive as opposed to having multiple parts.
What is an Autoloader?
Auto Loader is another innovative thought process from Databricks leveraging existing hyperscalers (AWS, GCP and Azure) technologies to incrementally and efficiently processes new data files as they arrive in cloud storage (S3, GCS, ADLS Gen 2 etc.) without any additional setup. Easy right? Indeed, it is easy when you leverage Autoloader. If not, then the process may be a bit lengthier.

Real life Example: You can go and build your own car. Most of us wanted a car from auto manufacturers that have an engine fine-tuned for performance, fuel efficiency, comfort, price and so on. Some of us may not like the factory installed sound systems, interior lighting that dances to our music or we just wanted to add after market performance boosters. The bottom line is that the car from the manufacturer, should be flexible enough to accommodate for after-market enhancements.
Databricks’ Autoloader gives you many out-of-the-box (OOB) capabilities while allowing you to customize/enhance to meet your needs.

If you wanted to build your own car and strongly believe you can build one better than the manufacturer, however, you may not get much benefit from this blog.
Everyone must ask two questions to your business and its true value. Do you need near real-time processing? The answer is Yes. Do you need real-time processing all the time? The answer is No.
Some examples for near-real time and / or batch process are receiving raw data from your electric meters aka advanced metering infrastructure (AMI), fitness watches, electric vehicles, advanced motor vehicles / mining / farming machineries equipped with thousands of sensors, weather data, health monitors, aircrafts, credit cards and so on, into cloud storage and processing them as soon as it arrives without manually establishing and managing complex technologies.
If any of you believe that it is too late to process the data after landing, but wanted to process the data while in-flight (aka data in transit). There are several options available such as Spark streaming (Check Databricks Websites and Google), Kafka Streams (Powered by KSQL, if you are interested, follow Kai Waehner who has number of articles for the confluent Kakfa streaming use cases), Azure Stream Analytics (Microsoft Site), Kinesis Analytics (AWS Site), Snowflake Streams etc.
Smart readers like you can make use of both options (data in transit processing and store & process in near real-time) to solve your special use cases.
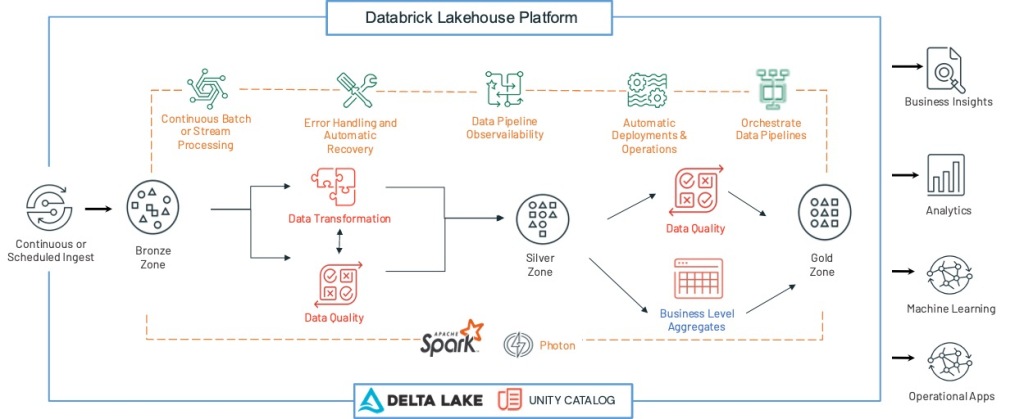
This blog is about what happens after the files land into the object storage (The Data Sources/Topics box in the above diagram) and how quickly it can be processed. Readers are encouraged to visualize the “ingestion” with this concept in mind.
Value Proposition of Delta Live Tables
Incremental Ingestions
No need to ingest files in a batch or scheduled mode. Prior to Autoloader, generally there are three ways the incremental data was processed.
Batch/Mini/Micro Batch: Applications are designed to read the ingested files from the object storage (S3, GCS, ADLS etc.) on a pre-scheduled interval, say every 5/15/30 minutes, or a few times a day. This has two issues; Increased latency and scheduling overhead. Some technologists innovatively developed a file watcher code that polls the directory for new file arrivals and triggered the next level processing, this is an intuitive and amazing thought process. But they also had to own the code, support, and tracking which files are processed, order of the files being processed, recoverability when fails, restarting from the point of failure, scalability and so on. The great news is that the great architects have designed a complex system to solve these issues. The Sky is not even the limit.
Notification (Trigger based): With cloud vendors’ event driven architecture, queues, notification technologies, lambda functions, etc. the near real-time reading of files became relatively better. But there is still a good amount of work involved to setup the items I have mentioned. They must track which files are processed, order of the files being processed, recoverability when fails, restarting from the point of failure, high performance reading, and so on.
Some technologists (ex. Databricks) thought that they can make the near real-time processing much simpler so the data engineers can focus more on higher order value services than spending time optimizing near real-time issues. They gathered every drop of water and that added up to a cup, if not a whole bucket full of water. The good news is that in enterprise, saving a cup of water on a large scale can be like saving a tank / container full of water when they must process large numbers of jobs that involve several thousand entities and several hundred thousand files.
Use Case(s)
- Process as soon as the files are ingested
- Never miss any files unintentionally
- Read only newly arrived files and never process old files by mistake
- Identify new files efficiently (Never use DIY comparison and check points)
- Handle Schema Inference and Schema Evolution
- Run as streaming or Scheduled / Batch
- Make it as repeatable (Parameterize)
Process as soon as the files are ingested
It is important to know that this requirement is not only processing the files as soon as they arrive but also without setting up any additional or complex services.
How would we do this normally? We would have metadata/ABC tables with last file being processed and continuously poll (aka heartbeat check) every 60 seconds or so for newly arrived files. Is there a way we can simplify this process without us polling, setting-up, and managing meta data tables? Yes, by leveraging Databricks’ Autoloader capabilities.
Autoloader triggers automatically while maintaining the order in which the files are being arrived.
Real life Example: You can go for a manual car wash, pre-wash your car, clean your tires, wash with soap, rinse, towel dry, and then apply wax. OR use a drive-thru wash and skip the hassle of manually making all the effort to wash your car. You have saved both time and money (manual wash cost higher when you take longer to clean).

Never miss any files unintentionally
When we manually setup the event driven architecture, we must make sure we did not miss any files as they arrive. We have the responsibility to make sure the files processed are matching with the files received. Traditionally, we store the metadata of all the files being processed and then we compare that against the directory listing to certify none of the files have been missed. This becomes trickier when applications must restart after any system related failures.
What if someone(something) takes care of all of these steps for us? (reading the directory faster, skipping the need to explain or prove to the audit team that all the files are processed and guarantee that they’re ready for business use with perfect data governance.)
Autoloader took care of this auditability without the need for us to maintain explicit ABC/Metadata management while improving the speed of the directory scanning.
What is this “unintentional”? If for some reasons if a particular file is bad, we need to stop the process since processing subsequent files may have negative consequences since order matters. What if we want to skip the bad file? This is where it gets tricky. You may need to move the bad file to a bad files location before you restart the process.
Real life Example: Let’s say you forgot to take the wax with you for the manual car wash, you will not be able to wax your car after the wash. You did not take the wheel cleaner, ditto! If you go to an auto car wash instead, they help you to avoid these minor inconveniences by having all these items in stock and ready to go. All you need to do is sit in your car under the cool lights, enjoy your music, and drive away!
Efficiently identify new files
Let us think about how we generally design the system to identify new files.
We will design a metadata framework to store last processed file marker (called a checkpoint). Then we list all the files in the directory to identify the files that are newer than our checkpoint and then start the process. One of the slowest processes is directory listing. When a directory gets bigger and bigger, the time it takes to scan the files will increase and thereby increasing data processing latency. The next slowest process is our own maintenance and management of meta data/ABC table.
What if someone else takes care of this without you working as hard to setup this functionality?
Autoloader processes only the new files without slow directory listing and never reprocesses the old files.
Autoloader process only the new files without slow directory listing and never reprocess the old files.
Real life Example: This is simple. The car wash gate will open if you are an existing pre-paid customer with a tag. If you are a new customer, you have pay it manually or to get a tag as a new customer in order for the gates to open! Do you think the gate opens if you keeping coming in cycles with a pre-paid tag? Interesting question for a healthy discussion. The answer is yes, for the most part, since every one of your entries is new entry. That begs the question. Is there a way to prevent people circling back into car wash? Is there a way we can check same file is coming back again and again?
Unfortunately, every time the file comes with a new entry into an object store (technologies know that you cannot have same file stored more than once when you overwrite a file, timestamp changes. It may be a valid overwrite so Autoloader picks it up).
How many car wash companies will instantaneously stop per-paid unlimited wash customers coming back in circles in real-time? None as far as I know. Is it worth it for them to add that intelligence in their system? Most likely not since it is very rare. Do they have analytics after the fact to find how many times we have washed our car in a month? If we exceed more than “x” visits, they will increase our monthly premium.
Of course, you can have after the fact validation to catch these errors as part DLT (Now you know how DLT is integrated with Autoloader). It gets complex and trickier if you want to prevent while ingesting!
Read ONLY newly arrived files
We can’t afford to have double counting even by mistake. It will have serious consequences such as audit issues, market impact and even penalties.
So, the architects designed the system by adding bells and whistles to the application like making an entry in the Audit, Balance and Control (ABC) tables as “Being Processed” so resubmitting the same job does not pick-up the file being processed and after completion or failure of the file, update the ABC table with status and so on.
Is there a better way to handle this use case scenario?
Autoloader process only the new files and never reprocess the old files.
Real life Example: You dropped your partner in a grocery store next to the car wash. You washed the car but get a phone call so you step away to take the call under some nearby shade. When your partner came in, partner saw the car was parked and starts washing it since your partner could not find you and assumed car has yet to be washed. Now you came back. We all know you did not say a word but you spent twice the money! That extra wash of the car is just more money out of your pocket!
Schema Inference and Evolution

Schema Inference: One of the bigger pain points of DIY metadata handling is storing metadata to read the files in a specific format. It works but is there a way we can eliminate the process if the application has the intelligence to infer the schema from the data files? This is not a new concept since we all know when we try to import CSV files, excel automatically determines the data types or if we have a header, it automatically adds the header. Years ago, we had to write a python code to do this work. The difference is that this became so easy in a way that we need to specify a parameter to infer the schema from a file or point to a location where the schema is stored. If you want to go even more details in addition to schema inference, you can also pass a hint if you know a specific column type (Example: double instead of an integer)

Schema Evolution: We all know that the source systems can add / remove the columns but may not notify us.
Use Case(s):
- Fail when new columns are added: Your Data governance team does not want the new column to automatically appear for end user consumption before they approve it. What if the new column contains Personally Identifiable Information (PII) data such as an SSN, DOB, etc.
- Add new columns: There are many objects that do not contain any PII data. Time to market will be impacted if IT takes weeks/months to add new columns. We need to have the columns/attributes appear as soon as source system sends a new file. This will update to the schema metastore.
- Data type changes: Sometimes, source systems make data type changes such as changing an integer to a double. We should be able to ingest without failing our flows.
- Ignore new columns: Do not bring in new columns. Just ignore them but do not fail the process.
- Rescue new columns: This is interesting. I do not want this to be added as regular columns (No update to schema metastore) but added a JSON string as a “_rescue” column. Why JSON? It is easy to store as many columns as we want as a single string that can easily be parseable.
Is there a better way to handle these use cases without developing a custom framework of code?
Autoloader has the capability to handle schema inference and schema evolution.
Real life Example: Let’s take a break from the carwash example for a second. You go to restaurant and customize your food to add or remove ingredients. As order comes by, the chef can add or remove ingredients as per the customer’s taste. I do this all the time going to an Italian restaurant asking them to change the sauce, add jalapeños (highly recommend you all do the same), remove mushrooms, replace angel hair pasta with Penne, add extra chicken, etc. My boss told me I ordered something from the Menu but nothing from the menu! But the chef can handle this, it’s just a simple Schema Evolution!
Most times, I walk into the restaurant with my friends, I get water without ice when others get water with Ice. They inferred from their experiences that I take water without ice. This is a prime example of Schema Inference!
However, when they gave same water without ice to our son; they failed to interpret it correctly since he was raised in a different part of the world than me. So when we go to the restaurant our son will add a hint that he needs water with ice. Schema Hints!
Run as Streaming and as a Batch
Use Case(s):
I need to load and process certain objects in
- near-real-time (always on)
- batch or scheduled mode (Cost control – As needed)
I want all of Autoloader’s capabilities including the ability in batch processing to add more business rules such as merging new data with old data leveraging the Delta foundation!
You can have Autoloader continuously watching and processing or scheduled at pre-scheduled intervals without missing any of these functionalities. New files uploaded after an Autoloader query starts will be processed in the next schedule. Autoloader can also process a maximum of 1000 files per every micro-batch. But there are other ways you can increase this rate limiting too.
Real life Example: Let us take the fast-food restaurant example. You can go and get it through drive thru or you can pre-order and pickup later at a scheduled time. Sure, you could say that we still have to wait at drive throughs, but this is the closest example I can think for fastest processing. In Autoloader, there is no wait time if you want to load immediately!
Make it repeatable
One of the greatest strengths of an architect is to design all the above functionalities as a parameterized repeatable process. We call them frameworks, assets, and accelerators. Why is this important?
- Eliminates redundant processes
- Consistent implementation across thousands of objects
- Developer bias and quality issues are eliminated
- Huge cost reductions since manual work is eliminated
- Speed to market so the objects can be delivered in minutes that days and weeks
- High quality outcome. Once tested; always provides guaranteed quality as opposed
Can we achieve all of the above benefits without architects investing their time and developer spend their time to develop all these capabilities? Indeed Yes.

Autoloader processes are configured to be repeatable.
Real life Example: Automated car washes are either touch or touch free. Cars are washed in the order in which they came in, the same amount of solution is being applied, all selected options are applied (tire wash, under carriage wash, wax and so on), and this process repeats for each car, more cars washed in short period of time and so on. Also, for the record, I don’t own a car wash!!
Jump on the Wagon?
Like any other technologies, one size does not fit all. You also need to understand when it is not going to be efficient. Same way you can’t take a sports car off-roading, you can’t expect every technology to work in every instance.
- Evaluate whether Autoloader fits your use cases.
- Gather all requirements. Sometimes, minor requirements may prevent leveraging Autoloader or vice versa.
- Event-based orchestration is useful but not in all use cases.
- Complexity increases when you have a dependency among data sources (In any streaming).
- Evaluate file handling failures. While Autoloader with the help of notebook development provides certain level of failure handling, it might increase the complexity.
- Understand limitations of hyperscalers’ infrastructure quotas and limits. For example, in Azure, Autoloader uses event grid topics. You need to understand resource limitations such as event subscriptions per topic, event grid publish rate (events/sec or size/sec) and custom topics limitations etc.
- Streaming optimization techniques to optimize the parallelism and size of streaming micro batch etc.
- How to manage how long the message to live in the queue (Time To Live – TTL) and what to do with the messages that can’t be delivered (Dead Letter Queue).
Recap
So what exactly Autoloader does?
- It stores the metadata of what has been read already.
- Leverages structure streaming for new real-time processing.
- It builds an infrastructure by leveraging a hyperscalers’ specific components without us needing to worry about anything
The power of Autoloader is not only meeting the above use cases, enabling the capabilities discussed but also providing the managed services while simplifying the multi-step and complex notification process for easy adoption. The goal is to make data engineers focus on leveraging the platform for higher order business benefits than spending their time on backend of the infrastructure configurations and management.
Please read the blog to understand how Autoloader and Delta Live tables are natively integrated to provide the “faster time to market” for the business.
Like any other products in the market, feedback from the field (Rubber meets the road) to Databricks is encouraged to enhance the Autoloader functionalities in its future releases. This will help us reap the benefits from the Databricks engineering investments.
Disclaimer
- While every caution has been taken to provide readers with most accurate information and honest analysis, please use your discretion before taking any decisions based on the information in this blog. Author will not compensate you in any way whatsoever if you ever happen to suffer a loss, inconvenience, or damage because of information in this blog.
- The views, thoughts, and opinions expressed in the blog belong solely to the author, and not necessarily to the author’s employer, organization, committee, or other group/individual.
- While the Information contained in this blog has been presented with all due care, author does not warrant or represent that the Information is free from errors or omission.
- Reference to any particular technology does not imply any endorsement, non-endorsement, support or commercial gain by the author. Author is not compensated by any vendor in any shape or form.
- Author has no liability for the accuracy of the information and cannot be held liable for any third-party claims or losses of any damage.
- Please like, dislike, or post your comments. This motivates us to share more to our community and later helps me to learn from you!
- Pardon for any grammar errors and spelling mistakes!