
I have really enjoyed writing these 4 blogs. It is an incredible journey. First time ever I had to split the blogs to provide a comprehensive view about each technologies and its evolution. Thanks to my friends who have pre-reviewed the individual blogs.
Last but not least, thank YOU all for traveling with me so far, your encouragements thru messages, posts, in-person, over the phone and all your likes in LinkedIn and WordPress. My blogs usually gets about 750 to 1,000 views but this topic doubled it and keep growing. I did not think this topic will generate so much interest. It was possible only because of all your motivation and encouragement. THANK YOU.

In this final cloud databases blog, we will try to address the challenges and concerns that are raised in the previous blogs regarding legacy and big data processing architectures.
Recap from Part III
- You want to scale the storage independently of compute and virtually unlimited(scalability) as well as share your storage to any number of computers aka CPU’s without physically attaching CPU to storage?
- You want to scale your compute independently of storage virtually unlimited (scalability), decide and change size of compute power to each person or group dynamically. If you add 10 CPU’s you should get 10 times faster response without any overhead.
- You want your compute not only scale independently but scale up and down based on your usage. And do not want to pay for entire compute power when you are not using it. You want the elasticity!
- You want the services that manages the platform to scale independently of your compute and storage.
- You don’t want anyone of unwanted the services running on your compute nodes which should be only dedicated to processing application needs.
- You want to store data once but share with many groups/environments. You don’t want to duplicate the data or in the business of sending data and managing all over heads. You also want the consumer to pay for their compute power which they can dynamically scale, and you don’t want to be in the business of sharing your compute power or managing service level agreements.
- You make mistakes but instantaneously you should be able to go back “n” number of days and get the data back as of that day.
- You want your backups are done automatically except in special cases.
- You want all your data to be encrypted, complete access management like any other databases you have without any security issues. Highly secured!
- Simply you want someone else to do all these for you and you want to pay per use. I think you want a Swiss bank!
- You want highly available and fault tolerant system.
Before you read further down, I just wanted to remind you that this is a blog. So it is almost impossible to write everything down here about cloud databases. We can go on and on and it will never stop since there are so much to talk about this technology and it is amazing!. When I chose the topic and added “I love it” in the title, I truly love it. If you want more conversation, catch me at drink time so we don’t need to worry about time, who is around us and what not?. But I will accept the invite only on the day when it “snows“. At the end, you make a call of who should pick up the tab?
I ran out of example with farming to expand further about cloud databases. I hope you all can travel with me technically in this blog after going thru the journey in the last 3 blogs.
There is also another surprise for you all. One of my long-term colleague expressed his interest to co-author this part of the blog with me. I am taking him with me in this journey. He is happy, but don’t tell him that I am taking him just to put a blame on him if anyone provides negative comments!. Just kidding. Happiness multiplies when we share!. Pleasure is mine!.
So what does cloud databases offer?. Everything in your wish list plus more(read the recap)
Yes and Yes.
In general, we love cloud databases including Google Big Query and what it offers. But we love snowflake little more (similar to your liking of two brands of beer but one has “little” more love from you than the other!. Sarang, the co-author do disagree on beer, he thinks it has to do with Santa Claus). Let us take some deep dive now.
Enterprise data does not live only on-premise any more with trends in big data, sales-force and many applications being now hosted on the cloud . Do we all agree on this one?. Also, enterprises have little or no control on 3 Vs (Volume, Variety and Velocity) of the data that is being generated. In later blogs we will address the other 2 Vs (Value and Veracity). Let us share some interesting fact for you to visualize the Vs.
“The average transatlantic flight generates about 1,000 gigabytes of data”.
One way / per flight. Do you see all 3 Vs here?. Volume of 1000 GB, Velocity at which it comes and the Variety of data from different part of the sensors.
To all Big Data experts (I know you have lot to say here), wait till you finish reading the blog in its entirety. Also read Part III of the blog where I have explained how big of a difference the Big Data technology made/making to us?. I am also one of you, so there is no intention of underestimating other technologies here.
To meet the need of Vs, data platform MUST scale.
It can’t be constrained by disk, CPU or memory.
This is where cloud’s elastic compute and its scalability makes its mark in the enterprise landscape. While we have few enterprise class cloud databases that leverages the cloud to its maximum, as we have mentioned, for simplicity and understanding we will pivot our discussion around Snowflake – The data warehouse built for the cloud.
We wanted to reiterate again that “our goal is to talk about Cloud databases” and not necessarily to support one cloud database over the other. Snowflake experience and in-depth knowledge helped us to develop the contents in a way that the readers can understand.
We will take you through our journey and also explain why we all fell for it. We also understand that we can’t do enough justifications for all of Snowflake’s functionality within this blog alone. We took a best effort only.
The features that tops our list are below. We absolutely love its architecture. We hope you will feel the same way when you finish reading this blog.
VIRTUAL WAREHOUSE
A “T-Size” cluster of compute resources in the cloud. A warehouse provides the required resources, such as CPU, memory, and temporary storage, to perform various operations.
How does this virtual warehouse helps the enterprises?. Let us take a use case. We all know, enterprises own one or more of SMP or MPP or Big Data platform to meet some imaginary / anticipated / projected workload. Let us know if you guys disagree or agree to disagree. You also know that we all have many different types of work load in our enterprises such as ETL aka data integration jobs, Business Intelligence (BI) tools accessing data for dashboarding and reporting, data mining team running the processes to discover patterns in large data sets, SQL analysts running large queries and Data Scientists running their predictive models against large volume of data. Oh. I forgot to mention the Data Wrangling tools used by the Business Analysts pulling huge volume of data and running the queries with unknown patterns!. Then the auditors don’t keep quite as well. They make sure we all will have special / on-demand audit or restatements data processing requirements to meet their standards. The list and types of workloads goes on!
All the above processes are sharing same resources constrained by a box you have purchased few years back and continuously upgraded to its maximum limit!. Experience has taught us; one single bad query can bring down the entire box or slows down EVERYONE ELSE. Let us not argue that you have a work load management in place and we all know what it means and how complex it is?. We all are used to hearing Oh!, that one rogue query brought the entire platform down and we need to reboot or restart or we missed the Service Level Agreements (SLA). Missing SLA’s not only causes bitterness from the consumers but also leads to heavy penalization for the delayed delivery as well.
How often we dreamed if we can scale up or down the resources dynamically based on the compute, space and memory as needed without impacting anything else going on in the system?. I am sure you all must have imagined for the “day” to come.
Let us take this even more. Would it be possible to have finer control and virtually unlimited expansion and also support the user needs separately and manage their own clusters based on their individual needs?. Yes! This is exactly what snowflake’s virtual warehouse does for you. Snowflake found the “magic key”.
The below diagram explains all we have talked about so far.
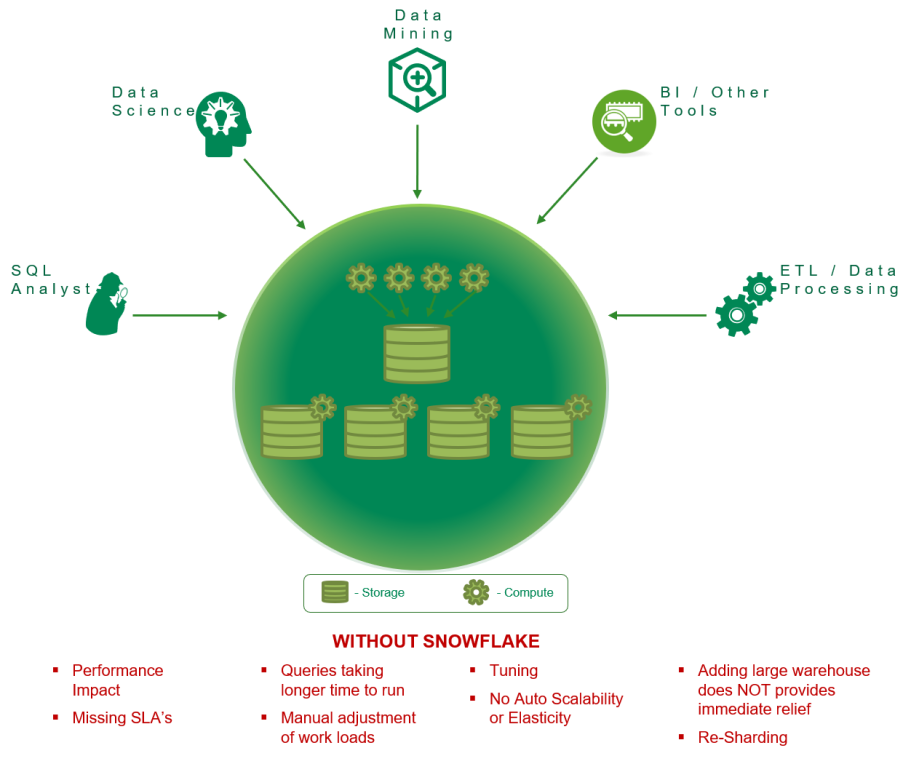
Figure – Day in the life of Enterprise Processing
How does this magic happen? Let us look at the architecture of Snowflake. Snowflake’s architecture is a hybrid of traditional shared-disk database architectures and shared-nothing database architectures.
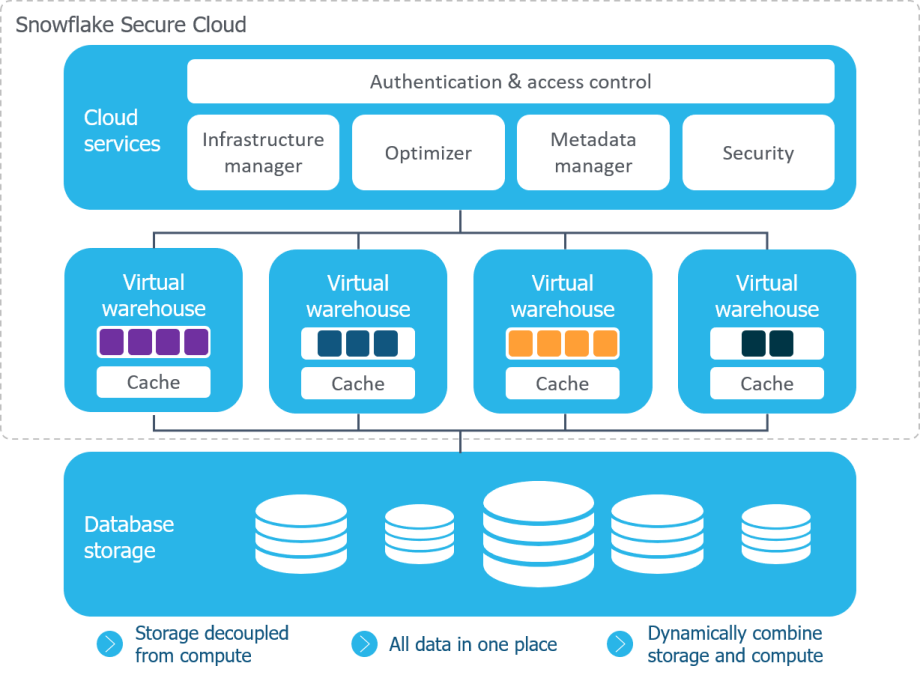
Figure – Snowflake Architecture – © Snowflake Courtesy
Make a note. There are 3 layers. Storage, Compute (Virtual Warehouse) and Services. All these layers SCALES INDEPENDENTLY.
Similar to shared-disk architectures, Snowflake uses a central data repository for persisted data that is accessible from all compute nodes in the data warehouse. But similar to shared-nothing architectures, Snowflake processes queries using MPP (massively parallel processing) compute clusters where each node in the cluster stores a portion of the entire data set locally. This approach offers the data management simplicity of a shared-disk architecture, but with the performance and scale-out benefits of a shared-nothing architecture©.
You can have a separate cluster (compute) for separate work loads but all sharing same data!. Have you noticed that “the storage is independent of compute”?. Any compute resource can access the storage since it is shared. For an example, each department can choose the size of their own compute resources based on their need but accessing same data.
Look at “Figure – Day in the life of Enterprise Processing” again. All these workloads can get its OWN dynamically scalable resources of compute and/or shared storage without impacting each other. Biggest differentiation and a huge leap.!
There are NO more issue of one rogue query brings entire enterprise operations down or missing any SLA’s!.
This is a great Segway for introducing the next top feature which is auto scaling.
AUTO SCALING
When the compute resources are not in use you can even shut down the cluster or scale it down. You pay nothing when you are not using the system. You pay only for what you use.!. There is no sunken cost. All are TRUE to believe; but it is TRUE.
With the traditional on premises solutions you must size and purchase hardware for maximum load based on anticipated / projected future load. This is where Snowflake’s ability to auto scale is impressive. Let us say you have “M” size compute resources for your regular work load. One fine day due to some government regulations, you are being asked to process 7 years of historical data to meet special auditing requirements. Just simply select the next big computing cluster size you needed just like selecting your “T-Shirt”. That’s all needed. Since you are storing all data in Snowflake / S3, there is no need to bring historical data from the tapes. If you have not kept all the data within snowflake / S3, then you have to have better plan to get the data first.
Snowflake makes it simple, next T shirt size simply doubles the processing power. Instantaneous scale-up!. Wow!. Once your historical processing is done, you can scale down immediately too. Scale up and down happens automatically as soon you make a request. We are sure many of you are already jumping up and down with a Joy.! You can change the warehouse size while the queries are running. When the warehouse size is changed, the change does not impact any statements, including queries, that are currently executing. Once the statements complete, the new size is used for all subsequent statement.
Advantages are limitless; Departments can have their own warehouses and can be billed separately. Remember the storage is shared so departments won’t create data swamps. Let me take it back, they can create more data and swamps if you don’t have a good data governance.! What we meant was that they have a choice to request more compute power without huge investment and pay for only what they use. Practitioners can now focus on data analysis, mining rather than worrying about size and CPU requirements.
Let us recap snowflake’s cloud database architecture.

Snowflake distinguished itself from other technology providers in providing some of the capabilities that are never existed before or as all inclusive.
Let us take another real life scenario?. How many weeks and/or months it takes the enterprises to setup separate environments for DEV, QA and PROD?. You all know.! Even after the initial setup is done, anytime when the lower environment need to be refreshed with production data, you will have to wait for another week or so in-spite of so many people working behind the scene to make the environment ready. One such example from our life was “some” enterprises took months to setup a performance test environment. Many places you can’t even copy production data to development environment without going through a bridge process (due to security reasons). We know you have a long list from your experiences too!.
You also needed separate infrastructure for these environments and separate people to manage. Have you heard about prod and non-prod admins, dba’s etc?. This is the biggest pain in the software / application development cycle. You don’t need to worry about this now. Snowflake allows you to stand-up the environments in minutes (if you want to add additional security and other items, add few more days for implementing data management processes) and WITHOUT DUPLICATING OR COPYING THE DATA.
It is called “Zero Copy Cloning”. You have to see it to believe it!.
ZERO COPY CLONING
You can create “n” different environments without even copying single bit!. Once you have your clone, you can make changes or add or remove anything in your environment. It is ONLY visible to you and all others will have their own data but there is ONLY ONE COPY of original data that was cloned. Same concepts applicable for the data security. You can apply common security on cloned objects and/or add more on top of this in your environment for your own needs. Is it not amazing?
So what is a clone and how is zero copy?. Clone does NOT duplicate the data. It is like a pointer to the original data of the time at which the clone is created. All the consumer can access their copy from the clone, add or modify or update more data or even combine with all other data they already have.
With the cloned copy, sky is your limit. You can select your own “T-size” clusters instantaneously to perform the operations you wanted to do (Analytics, data mining, Data Wrangling etc) based on your individual needs to get all your work accomplished.
Snowflake did not even stop there. They have added more gifts for the enterprise community.
How many times enterprises will have to share the data within the organization but do not want them to have access to the underlying data?. How many hundreds or thousand times we have to FTP/SFTP the files EVERY DAY for downstream or other consumers?. We all know we have dedicated systems and resources allocated just to perform these thousands of duplicate file transfers every day in every enterprises.
Not anymore. We know that you don’t believe it. Time to change!. “Zero Copy Cloning” will solve all your FTP / SFTP / File Sharing problems. *Remember your end user must have access to access the clone. If they are not the users of your snowflake eco system, you still need to have other file sharing mechanisms you have in your current enterprise system.
So what is called?. It is called “Data Sharing”.
DATA SHARING
How do we do that?. Simple. You just create a clone and give access to the consumers.!
This is an important concept because it means that shared data does not take up any storage in a consumer account and, therefore, does not contribute to the consumer’s monthly data storage charges. The only charges to consumers are for the compute resources (i.e. virtual warehouses) used to query the shared data.
We have been saying “Data has gravity and process does not”. This is why the revolutionary concept of data sharing is important; This new data sharing paradigm fundamentally disrupts the concept of data gravity.
We’re [Snowflake] now revolutionizing this [Data Sharing] and allowing people to share data between organizations without having to move the data. Nobody’s done that before. The future of data warehousing is data sharing.- Bob Muglia, chief executive, Snowflake.
PART III RECAP vs SNOWFLAKE
All your requirements and wish lists are addressed!

Time Travel
Pay little more attention to “Time travel”. It offers the benefits that was not easy to achieve or not possible in other technologies. We are very much excited and hope you will feel the same way once you understand this. Let us take another real life scenario we all will have to deal with.
What happens when your production processes updated (inserts, deletes and updates) set of tables in your database with the data that was identified as incorrect data?. The only way you can recover is to get the table data from the back-up as of yesterday (prior to updates), reload it and then reprocess with good data. You know how long it takes and how many people involved in it. What happens if you have to do this for several tables?. The problem multiplies. You became the “VIP” of the day from your senior leadership for all wrong reasons.
With “Time Travel”, you can access the point-in-time data instantaneously without going through the painful data backup and restore. The data retention period of each object specifies the number of days for which this historical data is preserved and, therefore, Time Travel operations (SELECT, CREATE…CLONE, UNDROP) can be performed on the data© . You can define the retention from 0 to 90 days, go back to ANY point-in-time data from 0 to 90 days instantaneously. A Big one!.
MORE
We have added more items than what you have asked for since we knew you will be asking us or challenging us soon.
SEMI STRUCTURED DATA
What about handling semi-structured data formats, such as JSON, Avro, ORC, Parquet, and XML?
Snowflake provides native support for semi-structured data, including:©
- Flexible-schema data types for loading semi-structured data without transformation
- Automatic conversion of data to optimized internal storage format
- Database optimization for fast and efficient SQL querying
CONTINUOUS LOADING / STREAMING
Snowpipe is Snowflake’s continuous data ingestion service. Snowpipe tackles both continuous loading for streaming data and serverless computing for data loading into Snowflake.
You pay only for the per-second compute utilized to load data instead of running a warehouse continuously or by the hour.
How about the number of clusters needed?. Does snowflake uses bigger cluster than what is needed or do I get charged higher for this special service?.. Not at all. Snowpipe automatically provisions the correct capacity for the data being loaded. No servers or management to worry about.
How about streaming (sub-second processing and storing)?. You can still achieve to an extend using Snowpipe but depends on what you are looking for. Some edge cases or special cases may need a different technology. You should think about your use case, whether snowpipe can help or not before you make a call on another technology because you get all other added benefits that comes with snowflake. This is a big topic for another time.
So what does cloud databases offer?. Everything in your wish list plus more(read the recap)
Yes and Yes.
FINAL THOUGHTS
Don’t assume one technology will solve all your issues. May be; maybe not. For an example, unstructured data. You have to use different technology to address this. You can’t have all kinds of competing technologies too since it is too much pain to maintain and we will be spending more time in debating which one to use. Just like you can’t have all kind of cars in your garage.
ALWAYS look at the big picture ,your E2E benefits (trust us and don’t ever do any comparison in isolation) and where others are heading into.
We have witnessed organizations and market leaders with all kinds of resources available at their fingertips lost the big time opportunity in the new technology area but others from nowhere captured the markets. We all have witnessed and witnessing downfall of big players just because they did not think proactively.
These new technologies will be very helpful , it is worth to take the risk and you are taking a calculative risk but a giant leap. Don’t wait for others to jump in or wait to learn from their mistakes. By that time you learn from others, either you are chasing them or the opportunity is lost. Get in there first and sure you will have some challenges at times, but it is worth. Of course life is full of challenges (including collaborating with the co-author!) only. But as technologist these are challenges that define us, groom us and humble us. Remember “Fail fast”.
“If there is no risk; there is no reward”
So don’t end up in a situation of chasing your competitors.
Summing this up; having previously worked with cutting edge technologies, proven experiences in building very large-scale data warehouses, big data platforms, cloud implementations and analytics systems from ground up, we would like to conclude with our own view and recommendations. Cloud databases like Snowflake are providing modern edge transformation technology that was not available before. Adoption of the cloud database technology will result in significant business benefits, positive impact to data driven enterprise and overall data management landscape.
So what are you waiting for?.
Embrace the new technology; you will loose nothing.!
Thank You Sarang for joining and your contribution as a co-author, specially for accommodating all my push and the revisions!
My next blog?. I am still debating between Technology or Leadership!.
Until then… Cheers.
- While every caution has been taken to provide readers with most accurate information and honest analysis, please use your discretion before taking any decisions based on the information in this blog. Author(s) will not compensate you in any way whatsoever if you ever happen to suffer a loss / inconvenience / damage because of / while making use of information in this blog
- The views, thoughts, and opinions expressed in the blog belong solely to the author(s), and not necessarily to the author’s employer, organization, committee or other group or individual
- While the Information contained in this blog has been presented with all due care, author(s) warrant or represent that the Information is free from errors or omission
- Reference to any particular technology does not imply any endorsement, non-endorsement, support or commercial gain by the author(s). Author(s) are not compensated by any vendor in any shape or form
- Author(s) have no liability for the accuracy of the information and cannot be held liable for any third-party claims or losses of any damage
- If you like it or dislike, post your comments. Former motivates us to share more to our community and later helps us to learn from you but neither is going to stop us!
- Pardon us for any grammar errors and spelling mistakes which we know there are many!
https://www.linkedin.com/in/manikandasamy/
https://www.linkedin.com/in/sarang-kiran-patil-pmp-pmi-acp-183b535/
